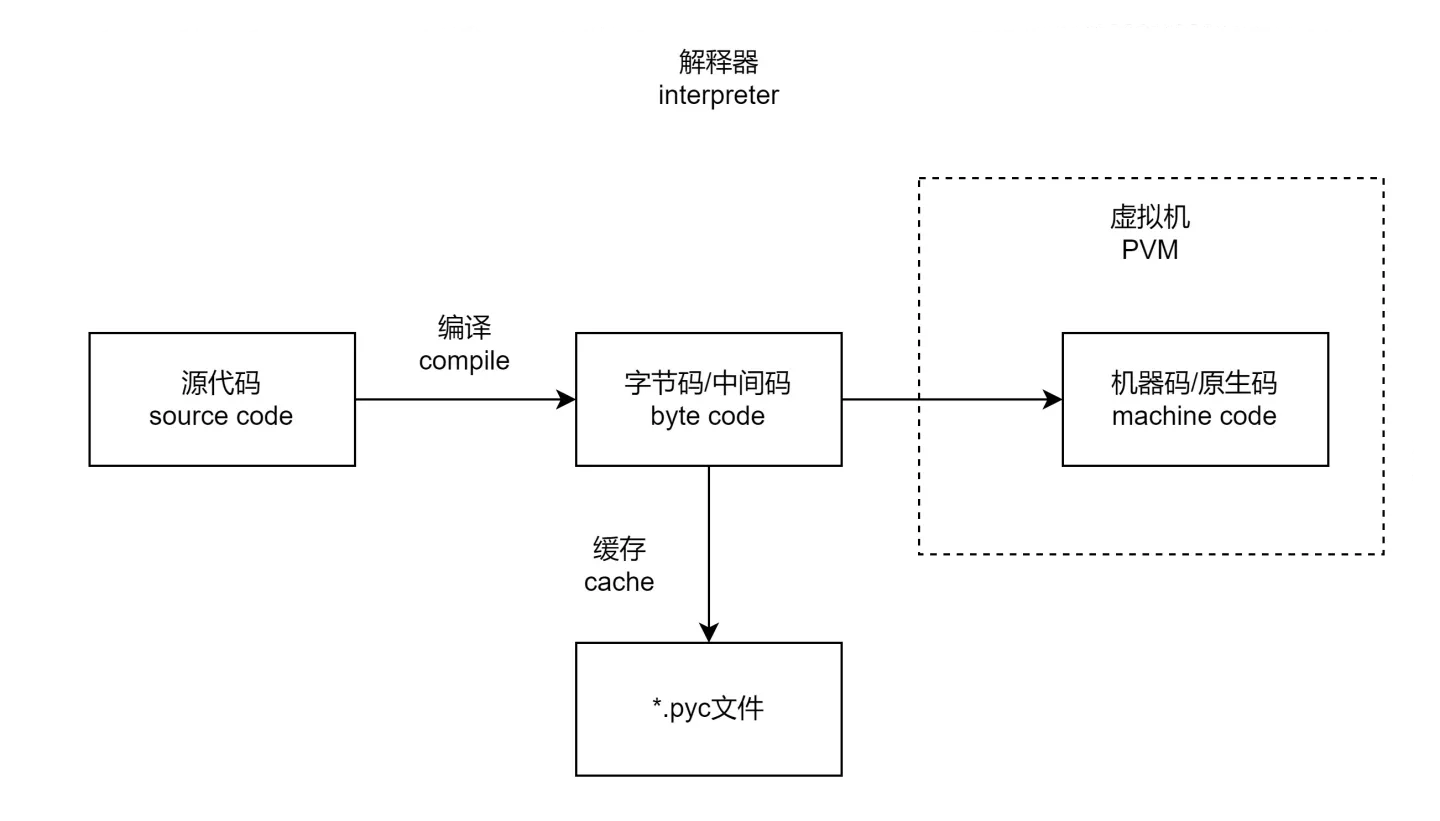
什么是进程?
进程是对资源进行分配和调度的最小单位,是操作系统结构的基础,是线程的容器(就像是一幢房子,一个空壳子,并不能运动)。
- 进程是一个实体,每个进程都有自己的地址空间,一般包括文本区域(text region)、数据区域(data region)和堆栈(stack region)
- 文本区域存储处理器执行的代码;数据区域存储变量和进程在执行期间所使用的动态分配的内存;堆栈区域存储在活动过程中所调用的指令和本地变量
- 进程是一个“执行中的程序”。程序是一个没有生命的实体,只有在操作系统调用时,他才会成为一个活动的实体:进程。
什么是线程
线程被称为轻量级进程,是操作系统能够运算调度的最小单位,线程被包含在进程中,是进程中实际处理单位(就像是房子里的人,人才能动)
- 一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆栈组 成。另外,线程是进程中的一个实体,是被系统独立调度和分派的基本单位,
- 线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,但它可与同属一个 进程的其它线程共享进程所拥有的全部资源。
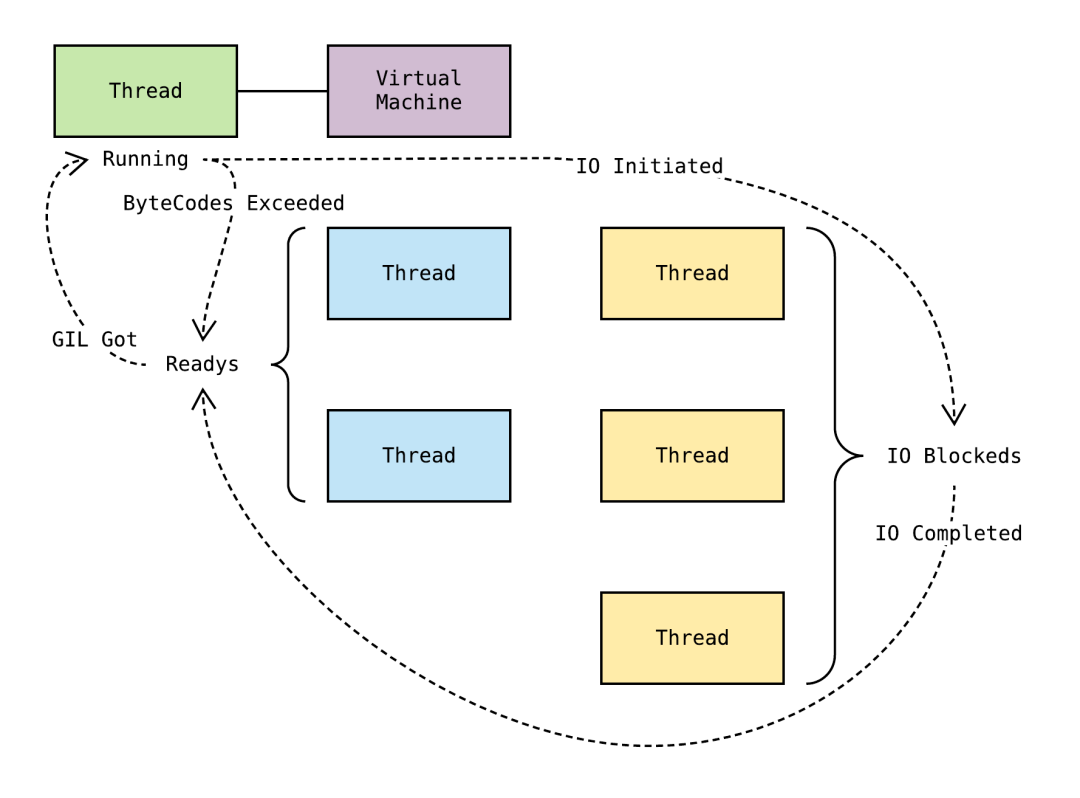
线程的三种状态
一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程 在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。
- 就绪状态是指线程具备运行的所有条件,逻辑上可以运行,在等待处理机;
- 运行状态是指线程占有处理机正在运行
- 阻塞状态是指线程在等待一个事件(如某个信号量),逻辑上不可执行。
- 每一个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
什么是协程
协程又叫微线程,一个程序可以包含多个协程,就好比一个进程包含多个线程。协程的调度完全由用户控制。
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
直接操作栈则基本没有内核切换的开销,可以不加锁的访问全局变量,所以上下文的切换非常快。
协程和线程的阻塞是有本质区别的。协程的暂停完全由程序控制,线程的阻塞状态是由操作系统内核来进行切换。因此,协程的开销远远小于线程的开销。
相互比较
进程与线程的区别:
-
- 进程有自己独占的地址空间,每启动一个进程,系统就需要为它分配地址空间;
- 而一个进程下所有线程共享该进程的所有资源,使用相同的地址空间,因此CPU在线程之间切换远远比在进城之间切换花费小,而且创建一个线程的开销也远远比开辟一个进程小得多。
- 线程之间通信更加方便,同一进程下所有线程共享全局变量、静态变量等数据。
- 而进程之间通信需要借助第三方。
- 线程只能归属于一个进程并且它只能访问该进程所拥有的资源。
- 当操作系统创建一个进程后,该进程会自动申请一个名为主线程或首要线程的线程。
- 处理IO密集型任务或函数用线程;
- 处理计算密集型任务或函数用进程。
线程和协程的区别:
- 一个线程可以多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程则是异步
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
我们常说python中的多线程都是假的,因为无论你启多少个线程,你有多少个cpu, Python在执行的时候会淡定的在同一时刻只允许一个线程运行。
这又是为什么呢?其实这主要是由于GIL的存在而造成的,详情查阅 http://bayestalk.com/592
总结
至此, 不难发现, 在某个角度来讲。它们三者体现的是一种颗粒粗细度的关系。就像切菜,
- 你用青龙偃月刀来切, 肯定是可以的, 但应该切得比较大块。
- 用菜刀, 这种对生活而言, 颗粒粗细度刚好。
- 但如果是做出蔬菜工艺品, 那么可能要用到非常小巧, 锋利的雕刻工具了。
再比如对于PC而言,
- 一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
- 有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
- 由于每个进程至少要干一件事,所以,一个进程至少有一个线程。
- 当然,像Word这种复杂的进程可以有多个线程,多个线程可以同时执行,多线程的执行方式和多进程是一样的,也是由操作系统在多个线程之间快速切换,让每个线程都短暂地交替运行,看起来就像同时执行一样。当然,真正地同时执行多线程需要多核CPU才可能实现。
大部分情况下, Python程序,都是执行单任务的进程,也就是只有一个线程。如果我们要同时执行多个任务怎么办?
- 一种是启动多个进程,每个进程虽然只有一个线程,但多个进程可以一块执行多个任务。
- 还有一种方法是启动一个进程,在一个进程内启动多个线程,这样,多个线程也可以一块执行多个任务。
- 当然还有第三种方法,就是启动多个进程,每个进程再启动多个线程,这样同时执行的任务就更多了,当然这种模型更复杂,实际很少采用。
多进程和多线程的程序涉及到同步、数据共享的问题,编写起来更复杂。
多线程编程
多线程编程导致的问题
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(1000000): # 循环的次数要设置得足够大。
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
run_thread(1)
print(balance)以单线程的思路来解释, 就是两个人玩一个非常无聊的游戏, A给B 1块, B又给A 1块, 重复无数次。 那么亿万年后, 他们的财产不会因这个游戏有任何影响。
- balance 初始值 = 0
- change_it(n) 函数
- balance+1
- balance-1
- 一加一减, 相抵消
- 所以最后balance
但是在多线程中, 而多线程中,所有变量都由所有线程共享, 任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量。
怎么解决?
import time, threading
# 假定这是你的银行存款:
balance = 0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(10000000): # 循环的次数要设置得足够大。
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
run_thread(1)
print(balance)结果始终为0, 不同线程间被lock隔绝吗相互独立, 互不干扰。
threading 类
Python的标准库提供了两个模块:_thread和threading,_thread是低级模块,threading是高级模块,对_thread进行了封装。绝大多数情况下,我们只需要使用threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start()开始执行:

其他
- 假设你经营着一家物业管理公司。最初,公司的业务量很小,事事都需要你亲力亲为,给老张家修完暖气管道,立马就去老李家换电灯泡—这叫单线程,所有的工作都得顺序执行。
- 后来业务拓展了,你雇用了几个工人,这样你的物业公司就可以同时为多户人家提供服务—这叫多线程,而你是主线程。
- 工人们使用的工具是物业管理公司提供的,这些工具由大家共享,并不专属于某一个人—这叫多线程资源共享。
- 工人们在工作中都需要管钳,可是管钳只有一把—这叫冲突。解决冲突的办法有很多,如排队等候、等同事用完后微信通知等—这叫线程同步。
- 你给工人布置任务—这叫创建线程。布置任务后你还要告诉他,可以开始工作了,不然他会一直停在那儿不动—这叫启动线程(start)。
- 如果某个工人(线程)的工作非常重要,你(主线程)也许会亲自监工一段时间;如果不指定时间,则表示你会一直监工到该项工作完成—这叫线程参与(join)。
- 业务不忙的时候,你就在办公室喝喝茶。下班时间一到,你群发微信,通知工人该下班了,所有的工人不管手里正在做的工作是否完成,都立刻下班。因此如果有必要,你得避免在工人正忙着的时候发下班通知—这叫线程守护属性设置和管理(daemon)。
- 再后来,公司规模扩大了,同时为很多生活社区服务,在每个生活社区都设置了分公司,分公司由分公司经理管理,运营机制和总公司几乎一模一样—这叫多进程,总公司叫主进程,分公司叫子进程。
- 总公司和分公司,以及各个分公司之间使用的工具都是独立的,不能借用、混用—这叫进程间不能共享资源。各个分公司之间可以通过专线电话联系—这叫管道。各个分公司之间还可以通过公司公告栏交换信息—这叫进程间共享内存。另外,各个分公司之间还有各种协同手段,以便完成更大规模的作业—这叫进程间同步。
- 分公司可以跟着总公司一起下班,也可以把当天的工作全部做完之后再下班—这叫守护进程设置。